CUDA - Compute Unified Device Architecture od NVIDIA
TLDR: Počítame veci rýchlo paralelne na GPU
Motivácia - Veľa vecí beží na grafických kartách
- Grafika
- Simulácie
- Ťaženie kryptomien
- 3D modelovanie
- Strojové učenie
De-motivácia - Vymyslieť niečo čo je reálne rýchle je zložité
- Veľa ľudí sa venuje optimalizácií kódu čo beží na grafikách, takže spraviť niečo fakt dobré je zložité
Setup
- Windows - na WSL - Nvidia Cuda na WSL
- Linux - Nvidia CUDA pre Linux
- Online - Ak nemáte GPU, tak viete Cudu spustiť cez Google-Colab - Geeksforgeeks Tutoriál
Základy jazyka C
Pointers
- Adresa premennej v pamäti -
&var - Hodnota na adrese -
*ptr
int val = 42;
int* ptr = &val;
ptr // Adresa v pamäti 0x...
*ptr // 42- Void pointers - vedia pointovať na hocičo a vieme meniť na čo pointujú, cez castovanie na iný typ pointru
void* vptr;
(int*)vptr; // Pointer na int
(float*)vptr; // Pointer na floatPOZOR NA
- Alokácie - musíme si overiť či boli úspešné
- Čistenie - po alokovaní si po sebe vyčistíme -
free()a nastavíme pointer naNULL
Štruktúry
Struct
struct Point {
float x;
float y;
};CPU intro
...
GPU intro
- Veľa jadier
- V realite sú ešte špeciálne jadrá - CUDA, TENSOR, RAY-Tracing
- Tensor jadrá sú špeciálne na maticové operácie (AB+C)
- Špeciálne časti na trigonometriu, iné operácie, ...
- Majú malý cache
- Veľa jednoduchých operácií
- FMA - Fused Multiply and Add
- Bit shifts, masky
- Proces - ako sa pracuje s GPU
- CPU - host dá GPU dáta
- CPU zapne GPU - device kernel (efektívne funkcia na GPU) a GPU to spočíta paralelne na dátach
- CPU si zoberie výsledok z GPU
Kernels - funkcie na GPU
Základy - naming conventions
h_A- premenná na CPUd_A- premenná na GPU__global__, __device__, __host__- funkcie ktoré sú všade, na GPU, na CPU -__host__sa nemusí písať
GPU pamäť
cudaMalloc- alokuje pamäť na GPU VRAMcudaMemcpy- kopírovanie dát CPU-GPU, GPU-CPU, GPU-GPUcudaFree__managed__- zjednodušuje prácu s pamäťou, zariadi aby bola dostupná z CPU aj GPU
nvcc Compiler
- Host code
- normálne kompilované CPU c/c++, manažuje GPU, pracuje s pamäťou
- Device code - frontend copiler
- PTX - parallel thread execution - univerzálny kód, virtual assembler
- SASS - source and assembly - pre jednu konkrétnu kartu
- JIT - just-in-time
- Kompiluje sa na natívne GPU inštrukcie
- PTX -> SASS - pri spustení
Zjednodušená CUDA Štruktúra - v realite 3D
- Kernel beží na Thread-e, každý thread má vlastnú pamäť
- Thread-y sú v thread Block-och
- Block-y sú v Grid-e
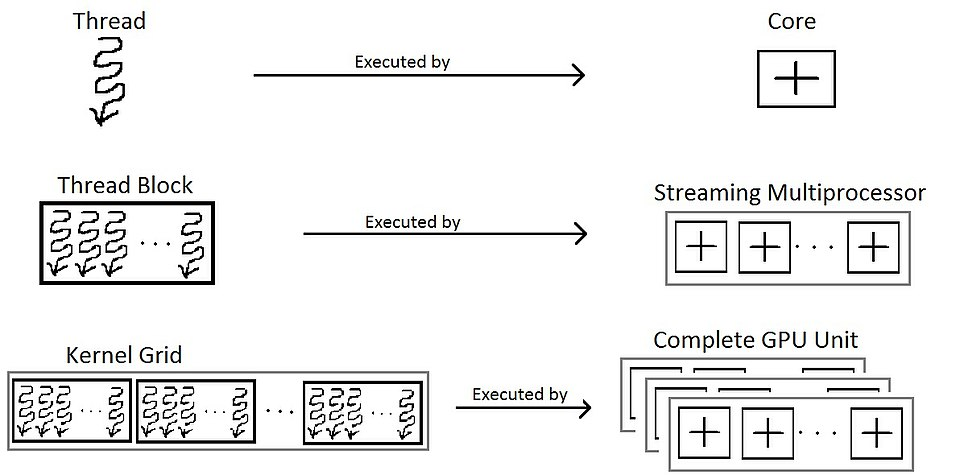
Threads
- Core beží thread, na threade bežia kernely/GPU funkcie
Warps - inšpirované tkaním
- V každom block-u sú warp-y - jeden warp paralelizuje 32 thread-ov v block-u
- Každý warp má warp scheduler - 4 na Streaming Multiprocessor/Block-u
- SIMT - Single Instruction Multiple Threads - každý thread má vlastný PC
- Lepšie rieši branch divergence
- SIMD - single instruction multiple data (stará verzia - všetky thready robia to isté naraz na iných dátach)
- Branch divergence - ak sa niekde vyskytne if-else
- musíme spraviť masku ktorá vypne niektoré thready a následne počítame if-else separátne
Blocks
- Block memory - L1 cache - zdielaná, relatívne rýchla, pre jeden block, 15TB/s
Grid
- Globálna GPU pamäť VRAM - 500GB/s-2TB/s
- z RAM do VRAM - výrazne pomalšie - 10-50GB/s
Synchronizácia
__syncthreads()- synchronizuje thread-y v jednom block-u, čakanie na thread-y v block-ucudaDeviceSynchronize()- synchronizuje celý grid, z CPU, čakáme na všetky thread-y__threadfence_block()a__threadfence_block()- zaručí že globálna pamäť bude jednotná pred fence-om
Atomické operácie
- Memory locking
- Proti race conditions
- Zariadi že sa operácia na nejakej pamäti vykoná predtým ako stým bude iný thread manipulovať
Streams
- Postupnosť inštrukcií z CPU tak ako sa vyhodnotia
- Stream 0 - ideme postupne, načítame, vyhodnotíme, ...
- Concurrency - máme viac stream-ov, vieme načítavať dáta počas toho ako počítame